


文章前的说明
本驱动针对NVIDIA环境,你需要有一张NVIDIA显卡,没有的可以略过了,请不要再问为什么我有INTEL/AMD核(独)显不能使用这个驱动了,因为这个驱动只针对NVIDIA GPU/vGPU设备。
注意:未经驱动源代码版权方Nvidia公司许可,不得将上述内容用于商业用途或侵犯版权行为。使用本驱动所产生的一切后果由用户自行承担,与提供者无关,本内容仅供学习研究使用。
注意:驱动有三种方式获取
- 矿神源中已上架: 矿神源
- Github地址:pdbear/syno_nvidia_gpu_driver
- QQ群(https://qm.qq.com/q/30uYiKaf7a)
为什么设置了一个加群获取的选项,而不放网盘里面?
- 群里面有很多的高阶玩家,当小白折腾出问题,可以有折腾过的人给出解决办法。
- 驱动本身关联硬件,里面很多细枝末节的问题作为玩家可能并不清楚,但群里总有人会知道。
- 有很多平台都可能看到我驱动更新的说明,但如果你折腾遇到问题,我并不清楚,所以无法解决你遇到的问题。
请注意:没有人有义务帮忙,本文中提到的点如果在群里发问可能会被人喷,可能会没人理你,所以请先仔细阅读教程。群友很乐意解决你在折腾的过程中遇到问题,发问时请注意科学提问,同时请注意发问的态度,请不要颐指气使,也请不要以老子天下第一还需要看说明书?的态度来发问,回答你问题的人每个都在这个领域里深耕多年,请尊重他人的帮助,谦虚面对自己不懂的问题。
为了维护良好的群体验,对于任何以我是小白,你必须解答我的问题的态度都会被踢出群。
这里借用zdm的朋友折腾核显驱动的回复,如果你真的折腾大型驱动,总会遇到这样那样的问题,受限于知识积累,你无法独立解决所有的问题,群就显得尤为关键,你可以向群友请教你遇到的问题。我也可以管生不管养,但我一路走来深知这折腾需要多少知识储备,建群只是不想看到你们像下面这样煎熬。
群里有很多大佬,如果你遇到的问题,他们以专业知识给予了完善的解答,请不要吝惜你的感谢,必要时可以发个小红包以示尊重他们的专业和帮助。
更新信息
详细已测试机型和显卡见 英雄榜: Synology Nvidia GPU/vGPU 成功案例
20250622
注意:如果安装之后显示“修复”,点击过后并无反应,这是因为没有授权导致的,请参考本文,使用simple premission进行授权
- 升级到550 cuda12.4版本
- 添加更多机型支持
20240719
- 升级到535 cuda12版本
- 修复控制面板中温度显示,数据来源是nvidia-smi中的温度,如果你的显卡比较低端没有这个数据或者VGPU场景,则控制面板中
GPU温度项目会因拿不到数据显示找不到设备。 - 此升级仅提供sign方式,请按照下文中
授权版本(xxxx-sign.spk)安装流程进行安装。 - DVA3221/3219如果要使用,请先关机拔掉显卡(虚拟机环境就取消vGPU/GPU直通),再按照正常安装流程,最后关机插入显卡(重新直通vGPU/GPU)启动。
- 这个授权(sign)是给套件授予ROOT权限的,jim佬做的,矿神那边现在也逐渐推荐用这种方式了。这种方式的好处是直接授予套件root权限,不用修复,后续升级无感,不是说要收费,看清楚了再喷。
20240310
- 修复docker报modeset问题
- 修复dmesg中大量apparmor deny报告
- 一个驱动包同时支持所有型号,包括RR自定义内核, 感谢@wjz304
- 适配权限管理包,不在需要修复,可通过simple permission manager进行授权,感谢@jim
20240209
- 升级525 cuda12
- 支持xs版本
20231117
- 支持sa6400,正在内测中,没问题一月后release。
20231105
- 525驱动正在内测
20230919
- 修复dva系列使用vgpu无法启动系统的问题。
20230916:
- 修复所有机型的GPU显示统计情况(按照下面的教程安装完驱动后需要重启生效)
- 支持白群
- 修复某些显卡可能存在的初始化问题
- 大范围测试更多的显卡。
20230906:
- 尝试支持白群。
20230902:
- 修复所有机型显示GPU使用/统计情况。
20230827:
- 修复重启机器后docker可能不正常的现象,修复可能发生的驱动不正常现象。
20230826:
- 物理群晖DS918+显卡1050、p4、40hx、2080、2080ti测试成功,DS1821+白群+1650测试失败(
暂未计划支持),0916版本已支持。
20230818:
- 几乎支持所有X86,4.0机型vGPU,直通(DVA3221,DVA3219)。对于直接物理群晖安装暂未适配(但可能是支持的)。
- 已测试支持机型: DVA3221,DVA3219(秀儿),DS918+,DS923+;期待各位朋友的测试和补充。
20230812:
- 理论支持DVA机型vGPU,直通,以及物理群晖,等待更多数据验证。
计划
- 初版的各种bugfix。 (已完成)
- 尝试支持更多的群晖。(已完成)
- pascal版本的群晖AI功能。(已完成)
- turing版本的群晖AI功能。(已完成)
- 后序版本升级支持和各种问题修复
结论
目前已经适配完成大部分的DSM系统,支持直通,vGPU,白群,物理黑群等大部分折腾会出现的常用配合。
底层驱动:vGPU 14.4(510.108.03)目前已更新至 525.105.17 cuda12(20240310) -> 535.154.05 cuda12.2(20240719)
支持显卡: 750Ti ~ 4090 这中间同芯片代数的都支持。不知道自己的卡是哪代的可以直接去nvidia官网查询。
授权:如果是,ESXi/PVE直通,白群,物理黑群,那么无需授权即可使用。授权只针对vGPU环境(vGPU即是一个显卡可切分成多份同时给多个虚拟机一起使用)。免费授权搭建:来自民间的VGPU授权fastapi-dls
支持群晖:大部分7.2系统的群晖,包括DS、DVA系列的(XS后缀不支持),其他系列暂未测试。注意:不支持小于7.2版本系统的群晖。
这里可以找到esxi和PVE使用的host驱动和windows、linux等使用的guest驱动:驱动下载地址
目前在群晖大部分平台上,适配了vGPU 14.4(510.108.03)和后序版本,底层需要使用>=你拿到最新版本群晖驱动(也即是版本更高的host理论都可以用,但是未全部测试所有的host,有反馈说最新的某些host版本是不可以使用的,如果你使用遇到问题,请尝试配套使用对应的host版本),只是如果需要详细的GPU统计显示效果,需要host和guest配套,群晖中需要安装本驱动。在tesla P4和2080Ti进行了测试,测试项目包括,(docker、openGL、编解码、群晖AI识别),由于DVA3221的Photos不会使用GPU,所以该包不影响该功能,目标:
- common:包大小500MB附近,无法使用群晖监控的AI功能,其他正常。(正常release,都可以使用)
- ai inside:包大小900MB附近,可以完整使用所有群晖的GPU功能。(目前仅提供给小部分支持皮蛋熊的小伙伴使用)
关键词:群晖 synology 英伟达 nvidia vGPU 虚拟GPU GPU共享
前言
最近佛西群的群友在讨论群晖是否可以使用Nvidia vGPU用于转码,人脸识别,AI等任务,看讨论结果好像是目前不可以。正好我对群晖的系统颇有好感,且对vGPU兴趣浓厚,所以在佛西群主、秀儿和几位大佬的支持下开始了探索行动。经过两个周末和一些零碎时间的探索,对于群晖支持vGPU已有一个明确的定论 -> 支持,但存在一些限制;探索之路曲折而漫长,耗费大量心血和头发的过程,想必各位网友并不关心,所以我直接切入主题,从安装开始讲起。
安装过程
特别说明:3221/3219版本一定需要先关机拔卡(直通用户先取消直通)再走安装流程,所有完成后再插卡开机(直通用户此时再直通)。
普通版本(xxxx-unsign.spk)安装流程(20240719之前的版本有这种安装方式):
- PVE/ESXi等Host(极力反对UNRAID)创建群晖虚拟机(此时请不要将vgpu/gpu分配(直通)给虚拟机)。
- 正常安装群晖虚拟机。
- 卸载系统自带的NVIDIARuntimeLibrary(如果有)
- 安装
皮蛋熊提供的驱动(ssh执行sudo vgpuDaemon fix-> 停止套件 -> 启动套件)。 - 关闭群晖虚拟机。
- 将vgpu分配给群晖虚拟机,然后启动群晖虚拟机。
注意:如果已经安装过本驱动并使用中,要升级最新版本的驱动需要按照下面步骤进行:
- 卸载本驱动(非常重要,需要先卸载)
- 安装皮蛋熊提供的更新版本的驱动(ssh执行
sudo vgpuDaemon fix-> 停止套件 -> 启动套件) - 如果你是vGPU环境,请选择
nvidia-xxQ这里的Q类型,以支持全功能显卡环境。 - 即可正常使用
授权版本(xxxx-sign.spk)安装流程:
- PVE/ESXi等Host(极力反对UNRAID)创建群晖虚拟机(此时请不要将vgpu/gpu分配(直通)给虚拟机)。
- 正常安装群晖虚拟机。
- 卸载系统自带的NVIDIARuntimeLibrary(如果有)
- 安装 simple permission manager 下载地址
- 安装本驱动套件(xxxx-sign.spk)
- 使用 simple permission manager 为NVIDIARuntimeLibrary授予Root权限。
- 停止本驱动套件->启动本驱动套件。
- 关闭群晖虚拟机。
- 将vgpu分配给群晖虚拟机,然后启动群晖虚拟机。
注意:如果已经安装过本驱动并使用中,要升级最新版本的驱动需要按照下面步骤进行:
- 直接网页上传新的安装包升级即可。
下面详细讲述安装步骤。
环境准备
配置介绍:
CPU:Intel i5-10400F
内存:32G DDR4 2400MHz
显卡:tesla P4 & 40hx & 2080Ti
系统:Proxmox VE 7.4
如果你不确定你的配置是否能够成功,可以参考下这里已成功小伙伴的配置:已成功小伙伴光荣榜,或者加群问问群友。
在这套硬件平台上安装了PVE虚拟化环境,并使用 vgpu_unlock 项目,该项目使得消费级显卡比如2080Ti的环境下也可以体验Nvidia vGPU。推荐使用vGPU是因为可以多个虚拟机共享算力,并非本项目只支持vGPU,而是所有你能想到nvidia + 群晖组合都基本都支持。
注:如果想要使用vGPU/GPU,我推荐host平台为PVE或者ESXi,极力反对UNRAID(我就是正版的UNRAID受害者,内核问题几年都修不好,新版本直接引入天量BUG),任何host是UNRAID问问题的一律不理!可以查找关于安装PVE和vgpu_unlock的资料,也可参考下面佛西大佬的博客:
- 在Proxmox VE 7.4 中开启NVIDIA P106显卡虚拟化(VGPU)
- 来自民间的VGPU授权fastapi-dls
- 在Proxmox VE 7.2 中开启vGPU_unlock,实现显卡虚拟化
群晖安装
在PVE中创建虚拟机(这里你完全可以使用物理机,该驱动同样可以工作),并正常安装群晖DSM,这里的教程可以参考大部分的PVE使用ARPL安装群晖的教程,可以在张大妈上搜一下(这类文章截图多,小白向更好),比如我随便搜了两个:
当然最权威,最有价值的文章,仍然是Lng大佬页面:
特别提醒:
- 如果要使用群晖监控,请准备好正确的序列号,不然安装后授权是0。
- 群晖系统安装时,请不要将vGPU/GPU传递给群晖虚拟机。
- 如果是安装DVA3221等DVA机型,请先拔掉显卡(取消直通,或者取消GPU引入系统),所有操作完成后再安装显卡!
普通版本(xxxx-unsign.spk)驱动安装
群晖正常安装完成后,DVA系列会自己安装NVIDIARuntimeLibrary和Surveillance,需要先对其进行卸载(其他DS系列不会)。如果你是第一次安装,大概率会因为没有创建存储而不会安装。所以此时创建了存储即可安装该vGPU驱动包。
如果在已有群晖数据的硬盘上重装了系统,此时系统默认会安装NVIDIARuntimeLibrary和监控,这里需要等待其安装完毕后,确认监控的可用路数是否正确(是0的话是序列号有误);一切正常后即可删除NVIDIARuntimeLibrary和监控,然后安装本驱动包。
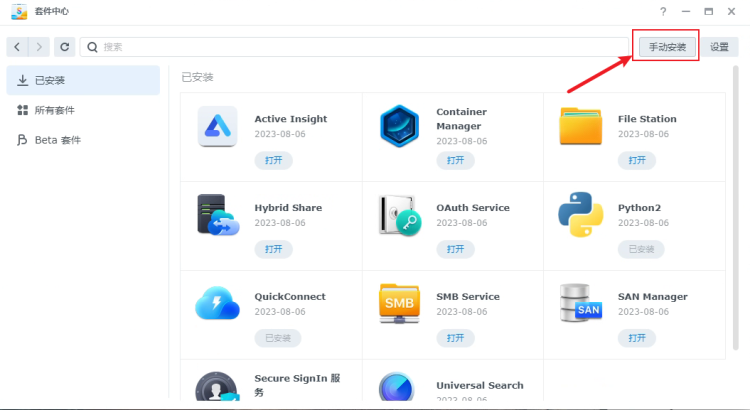 到这一步时,请修改为你的授权服务器地址(还没搭建?可以参考佛西大佬的博客) 来自民间的VGPU授权fastapi-dls
到这一步时,请修改为你的授权服务器地址(还没搭建?可以参考佛西大佬的博客) 来自民间的VGPU授权fastapi-dls
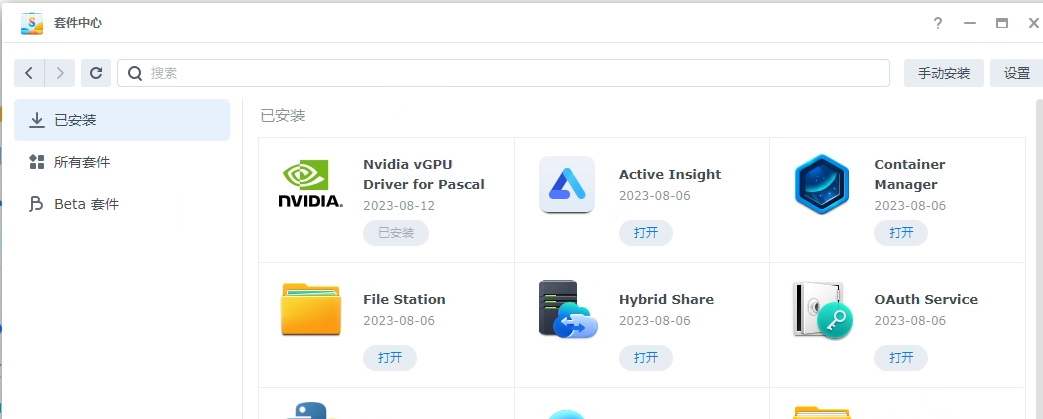
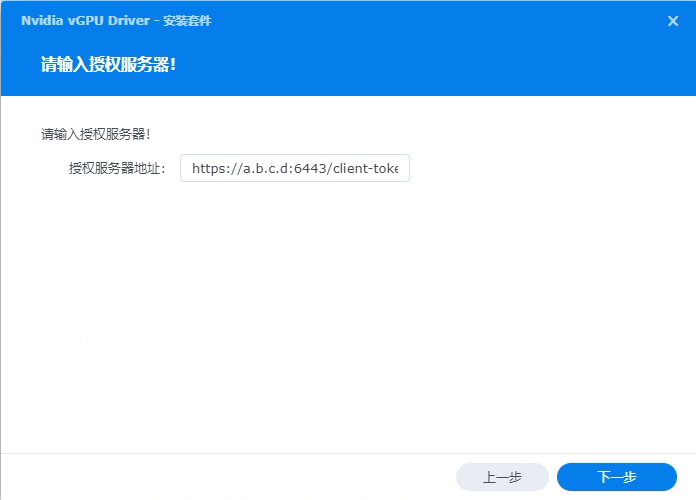 安装完成后可看到新安装的驱动:
安装完成后可看到新安装的驱动:
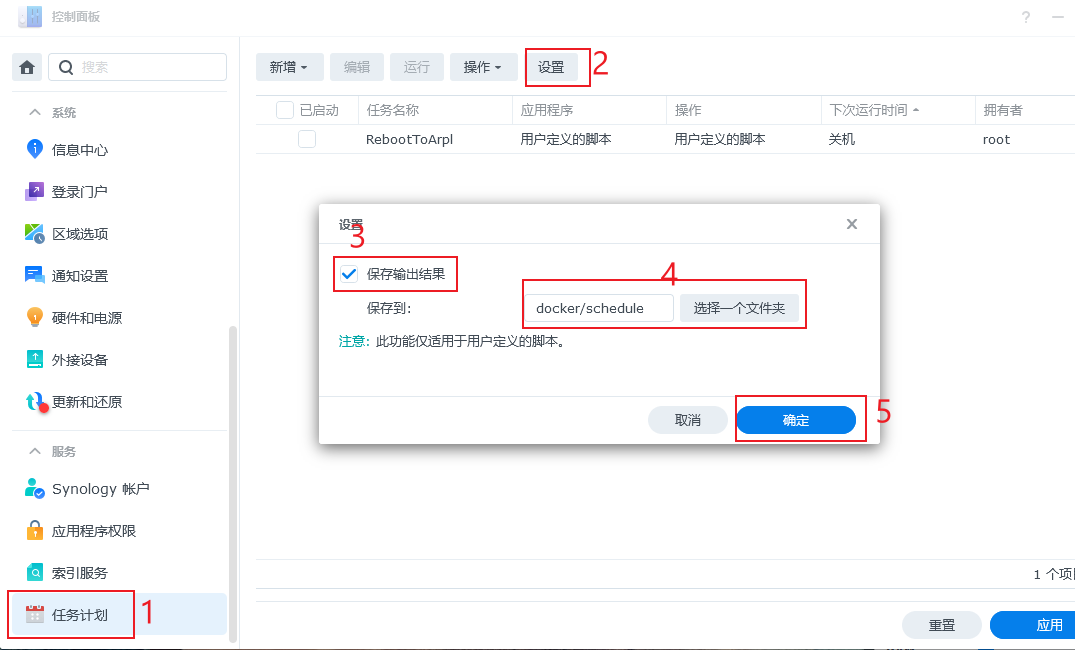
 此时我们进入任务计划中,点击设置,勾选保存输出结果,选择保存到一个目录中,这里选择一个临时目录(这里我在
此时我们进入任务计划中,点击设置,勾选保存输出结果,选择保存到一个目录中,这里选择一个临时目录(这里我在docker目录中建了一个schedule目录)即可。
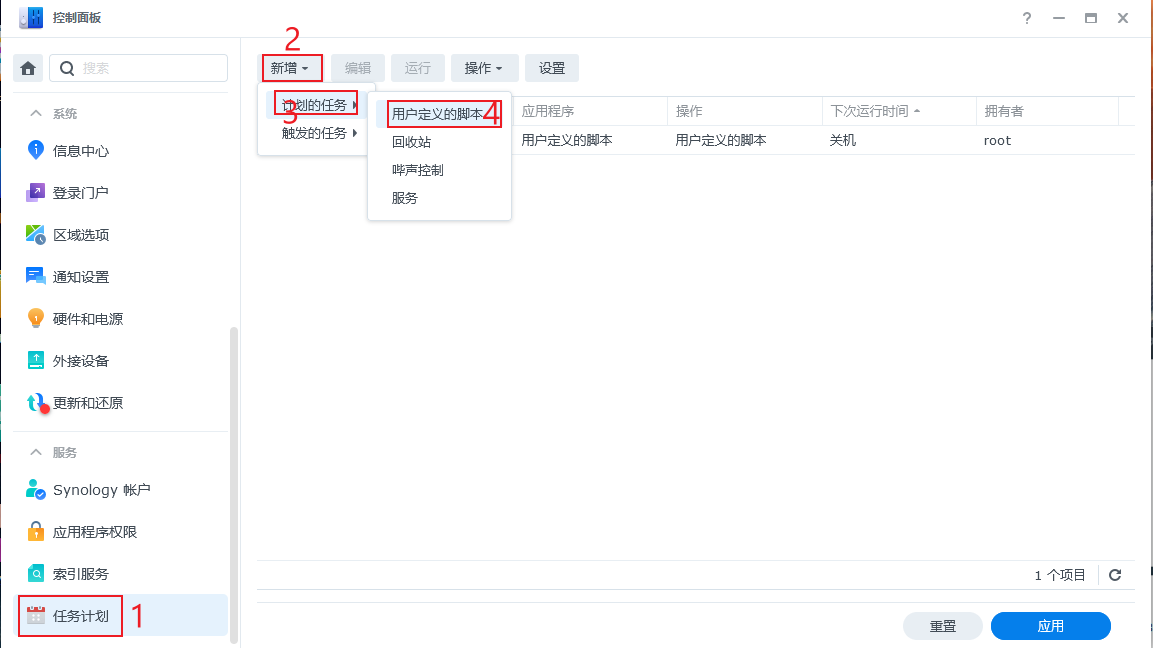
 此时进入群晖的控制面板->任务计划->新增->计划的任务->用户定义的脚本
此时进入群晖的控制面板->任务计划->新增->计划的任务->用户定义的脚本
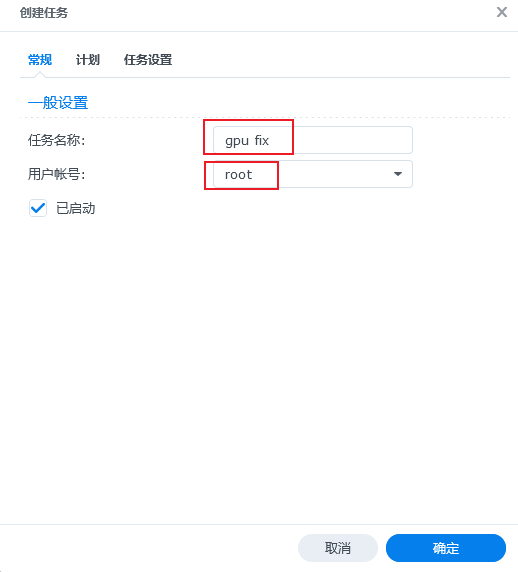
 我们创建一个修复驱动的任务,命名为
我们创建一个修复驱动的任务,命名为gpu fix,用户账号一定要修改为root:
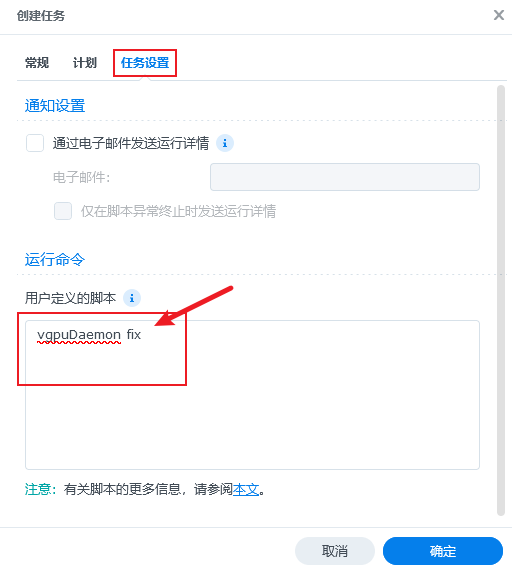
 转到任务设置中,我们在
转到任务设置中,我们在用户定义的脚本中输入vgpuDaemon fix,然后点击确定:
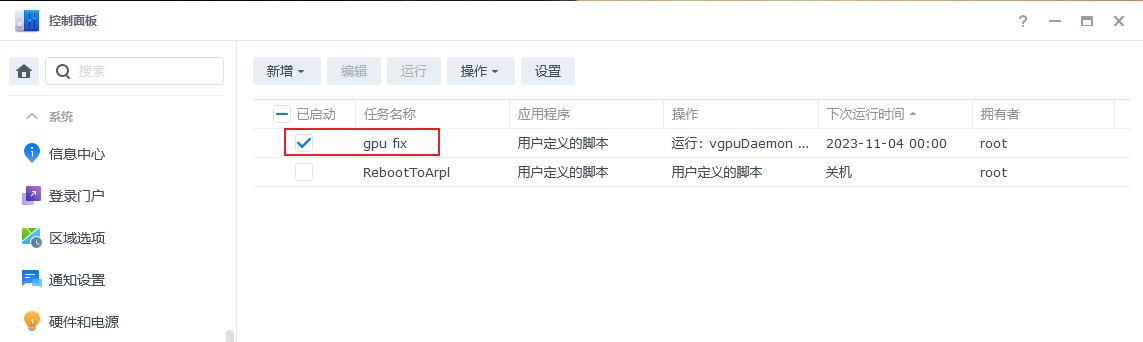
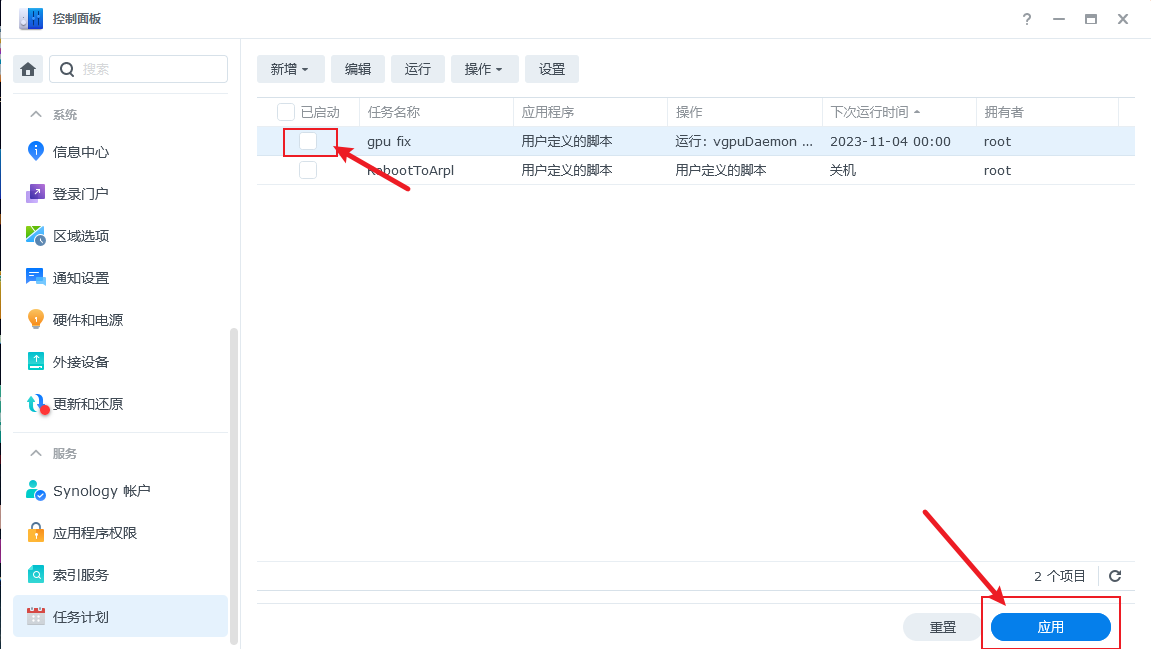
 此时我们可以看到建立好的任务:
此时我们可以看到建立好的任务:
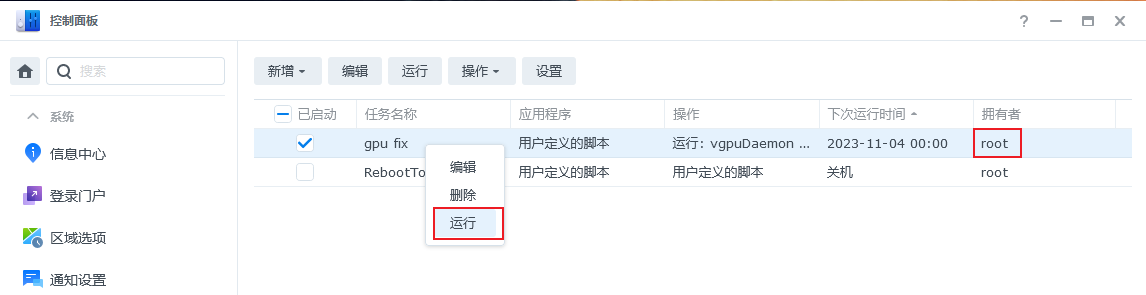
 这里我们使用鼠标指向我们新创建的任务,鼠标右键选择
这里我们使用鼠标指向我们新创建的任务,鼠标右键选择运行。
 运行完了以后,我们需要取消这个这个任务,我们取消前面的选择框,并点击确定。
运行完了以后,我们需要取消这个这个任务,我们取消前面的选择框,并点击确定。
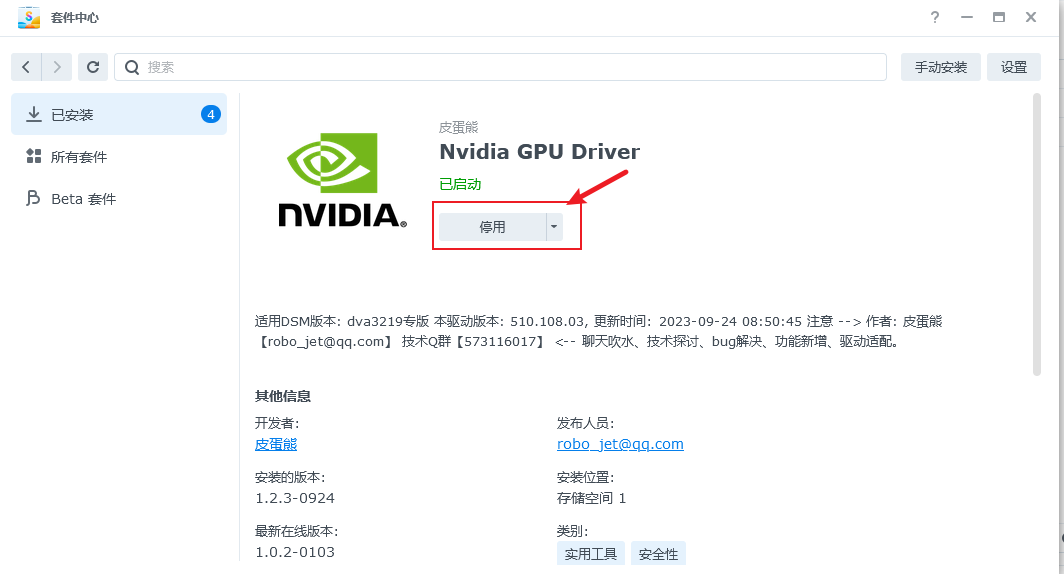
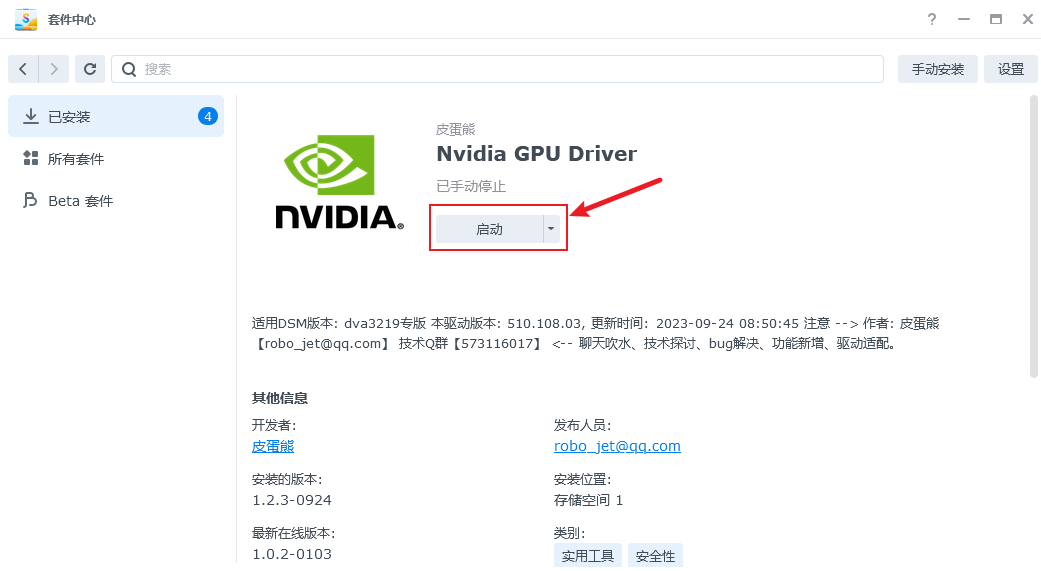
 此时进入套件中心,停用本套件,然后紧接着启用本套件:
此时进入套件中心,停用本套件,然后紧接着启用本套件:
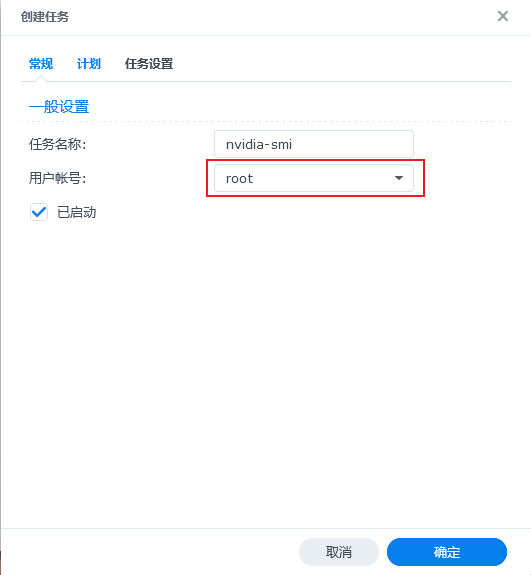
 此时我们再次回到控制面板->任务计划,和上面操作一样,创建一个
此时我们再次回到控制面板->任务计划,和上面操作一样,创建一个nvidia-smi的任务,如下图,填入必要信息nvidia-smi:
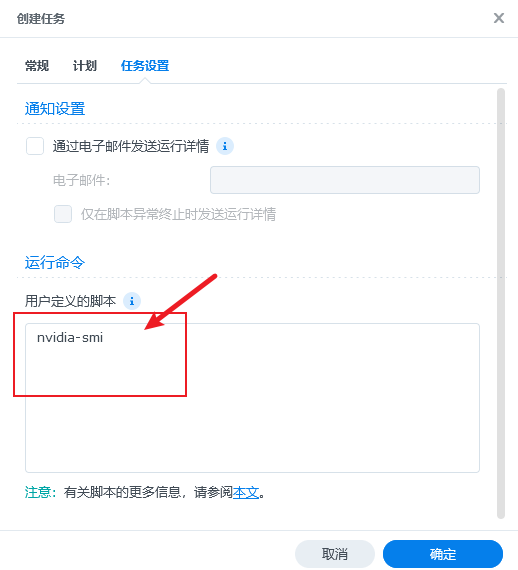 右键运行
右键运行
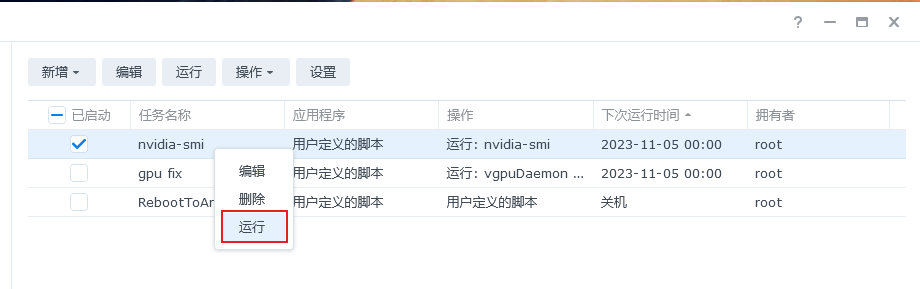 运行后,我们可以点击这条任务,再点击操作,选择查看结果
运行后,我们可以点击这条任务,再点击操作,选择查看结果
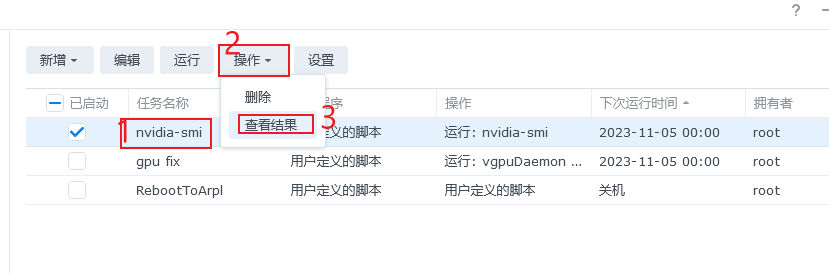 就可以查看到运行结果。
就可以查看到运行结果。
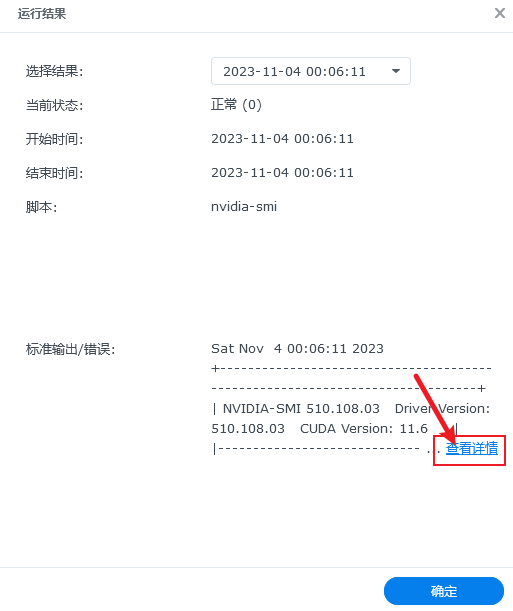
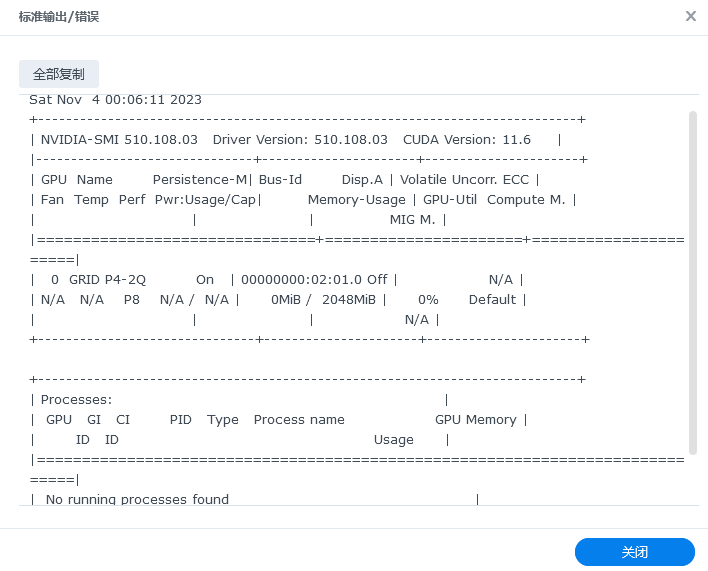 如果你出现了上面类似的结果,表示驱动已经正常使用了。此时请和上面一样,取消这个任务的启用,并点击应用,也即是这个任务只需要执行一次就可以了。
如果你了解linux系统,也可以在终端中输入
如果你出现了上面类似的结果,表示驱动已经正常使用了。此时请和上面一样,取消这个任务的启用,并点击应用,也即是这个任务只需要执行一次就可以了。
如果你了解linux系统,也可以在终端中输入nvidia-smi命令看到同样的输出信息。
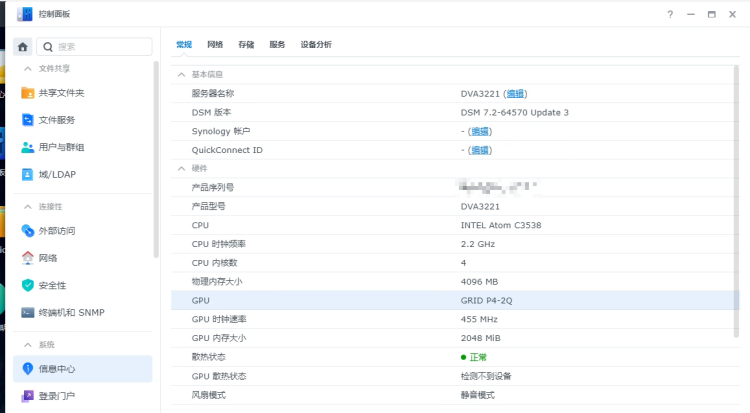
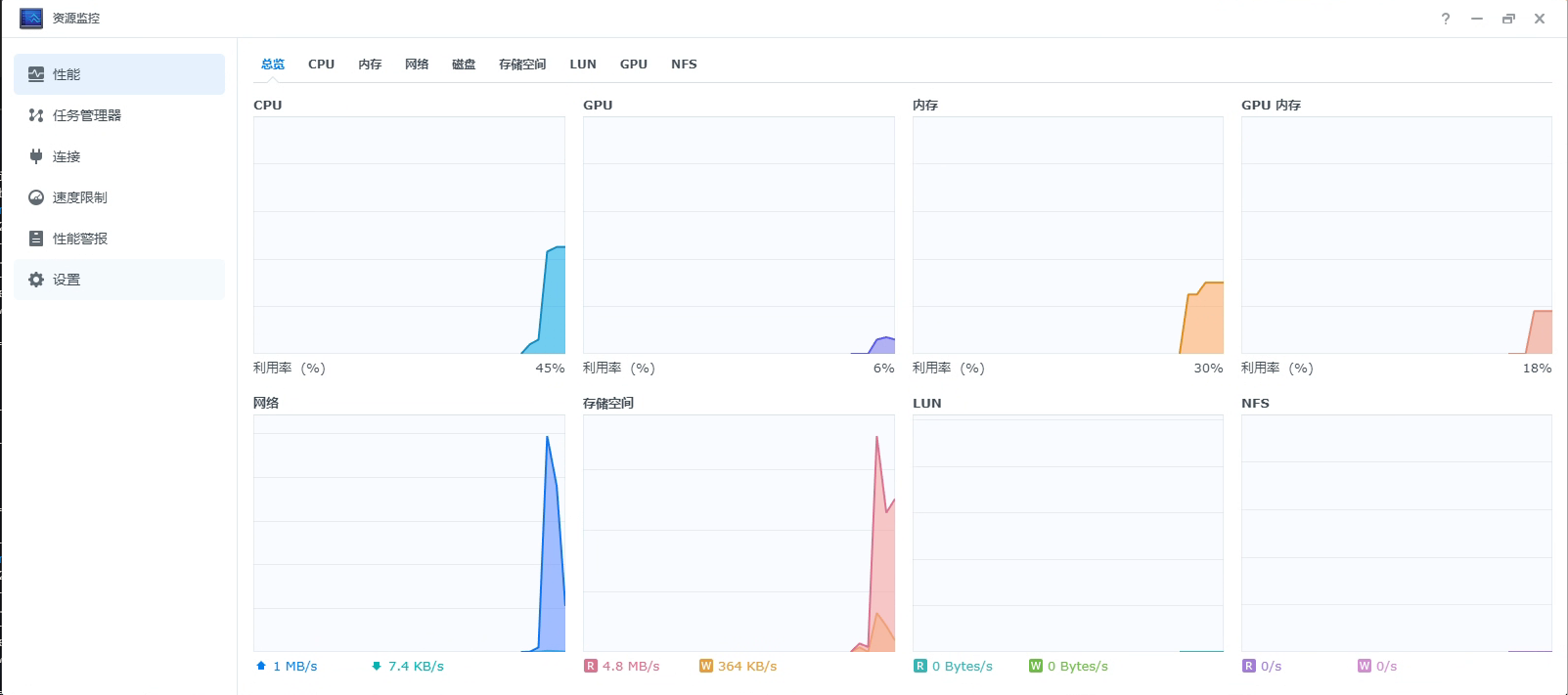
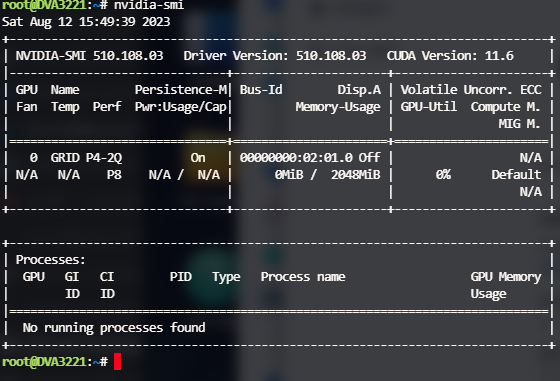 此时非DVA系列机型需要重启系统,重启后群晖系统也可以正常识别到GPU的相关信息:
此时非DVA系列机型需要重启系统,重启后群晖系统也可以正常识别到GPU的相关信息:
授权版本(xxxx-sign.spk)驱动安装
群晖正常安装完成后,DVA系列会自己安装NVIDIARuntimeLibrary和Surveillance,需要先对其进行卸载(其他DS系列不会)。如果你是第一次安装,大概率会因为没有创建存储而不会安装。所以此时创建了存储即可安装该vGPU驱动包。
如果在已有群晖数据的硬盘上重装了系统,此时系统默认会安装NVIDIARuntimeLibrary和监控,这里需要等待其安装完毕后,确认监控的可用路数是否正确(是0的话是序列号有误);一切正常后即可删除NVIDIARuntimeLibrary和监控。
在这里下载好simplePermissionManager并安装 下载地址
安装好后可以在这里看到套件
 点击此套件,激活并输入密码
点击此套件,激活并输入密码
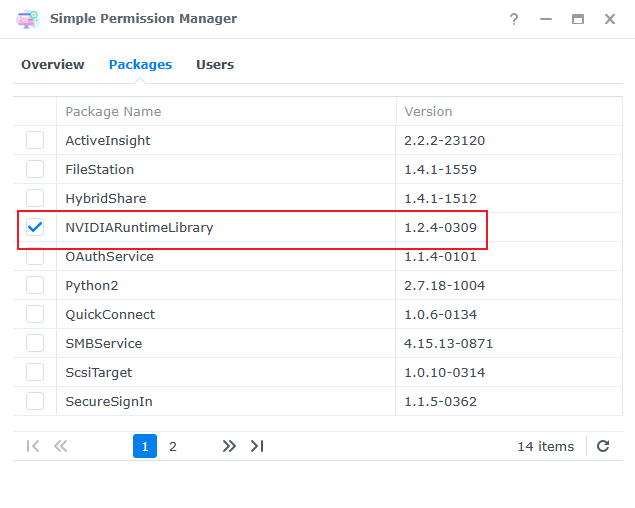
 此时安装驱动套件(xxxx-sign.spk)
此时安装驱动套件(xxxx-sign.spk)
 回到SimplePermissionManager对驱动套件进行授权。
回到SimplePermissionManager对驱动套件进行授权。
 此时重启一下驱动套件即可。
此时重启一下驱动套件即可。
docker安装
如果系统原来就已经安装了docker(Container Manager)套件,此时只需要停止下该套件,然后重新启动该套件即可。
如果系统是新的,没有安装Container Manager套件,此时需要先安装该套件;安装完成后,将本套件停止再启动。
这里更为推荐使用docker来启动服务,主要是不会污染主机环境,运行简单,不会对其他程序造成冲突。
docker compose版emby安装
这里以emby作为例子进行举例(特别感谢专吃硬解大佬提供此更为友好的方法),优点是你更新了docker容器仍然不影响gpu的使用(如果是使用下面命令行的方式会受影响):
这里我们首先建立一个docker配置文件的存放目录:
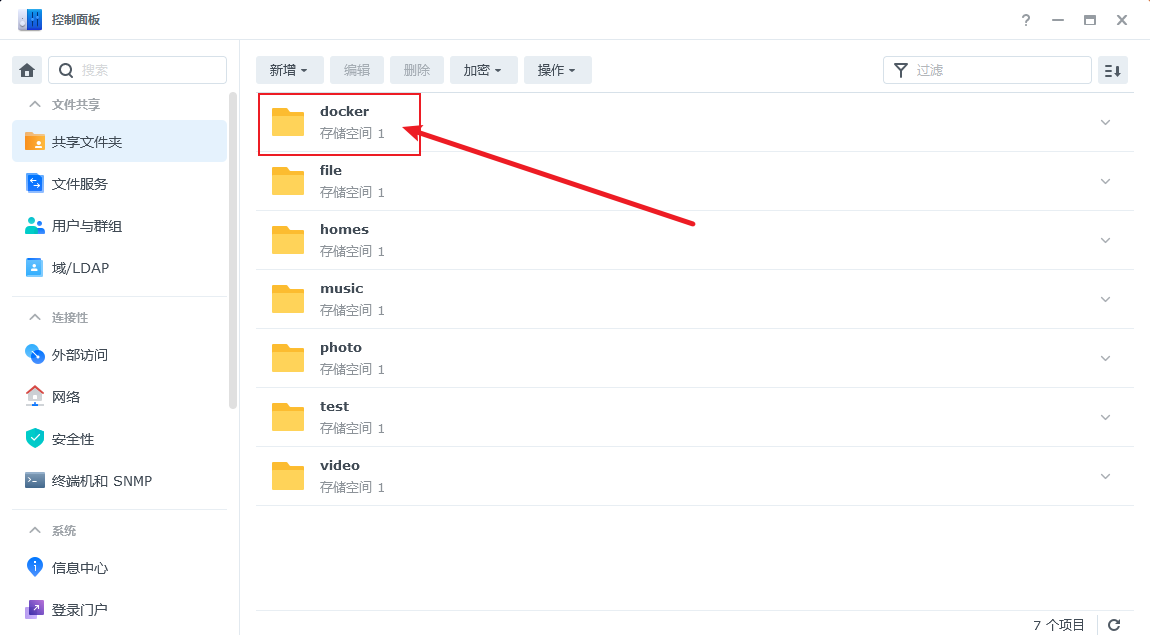 再创建
再创建emby_server目录和在emby_server目录下创建config目录,如下图所示:
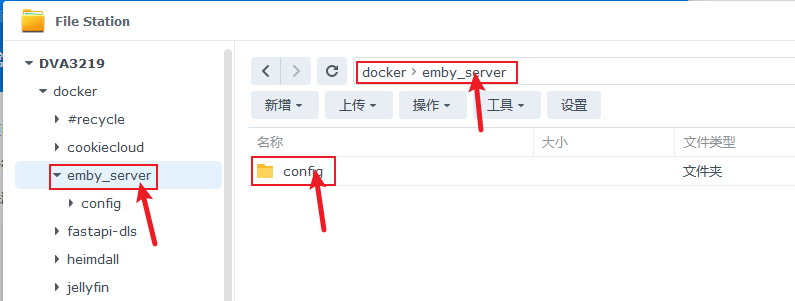 此时我们可以回到
此时我们可以回到Container Manager中点击项目-> 新增,进入如下界面:
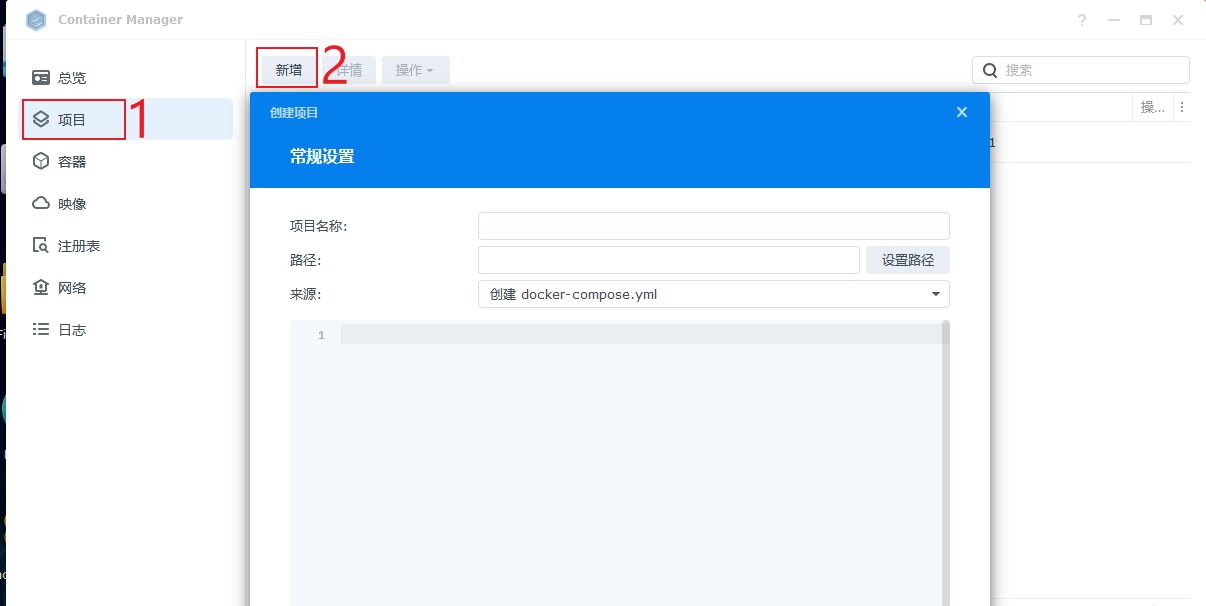 填入如下信息,并选择到刚才创建的
填入如下信息,并选择到刚才创建的emby_server/config目录,来源,创建docker-compose.yml中:
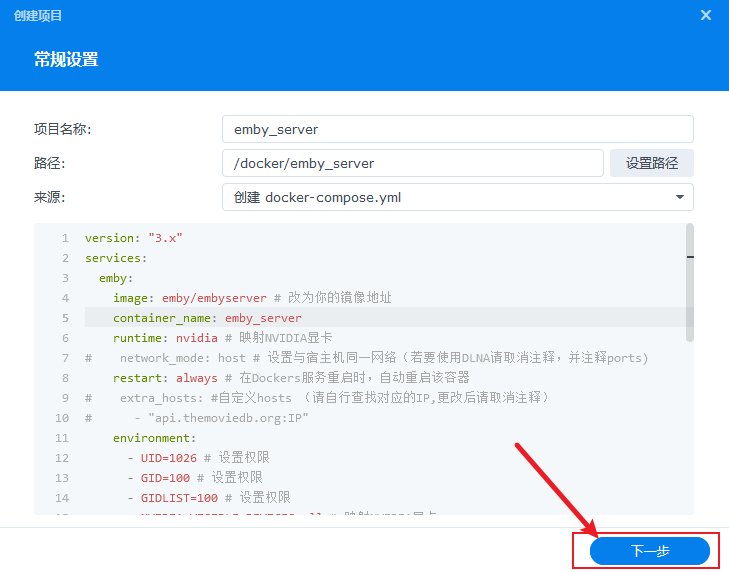 下面的具体内容如下,如果看了注释不懂每个条目是什么意思,可以去群里请教其他小伙伴:
下面的具体内容如下,如果看了注释不懂每个条目是什么意思,可以去群里请教其他小伙伴:
version: "3.x"
services:
emby:
image: emby/embyserver # 改为你的镜像地址,你问我开心版这里填啥?这就要问群友去了。
container_name: emby_server
runtime: nvidia # 映射NVIDIA显卡
# network_mode: host # 设置与宿主机同一网络(若要使用DLNA请取消注释,并注释ports)
restart: always # 在Dockers服务重启时,自动重启该容器
# extra_hosts: #自定义hosts (请自行查找对应的IP,更改后请取消注释)
# - "api.themoviedb.org:IP"
environment:
- UID=1026 # 设置权限
- GID=100 # 设置权限
- GIDLIST=100 # 设置权限
- NVIDIA_VISIBLE_DEVICES=all # 映射NVIDIA显卡
- NVIDIA_DRIVER_CAPABILITIES=all # 映射NVIDIA显卡
volumes:
- /volume1/docker/emby_server/config:/config # 映射配置目录
- /volume1/video:/mnt/video # 映射媒体库目录
ports:
- 8095:8096 # 映射HTTTP端口
- 8919:8920 # 映射HTTTPS端口
请将这个值复制到上面图中的对应部分。正常点击下一步后会进入门户设置,这里直接下一步,不需要设置:
 单击完成
单击完成
 此时系统将会开始构建,等待最后输出
此时系统将会开始构建,等待最后输出Exit Code:0就表示成功了
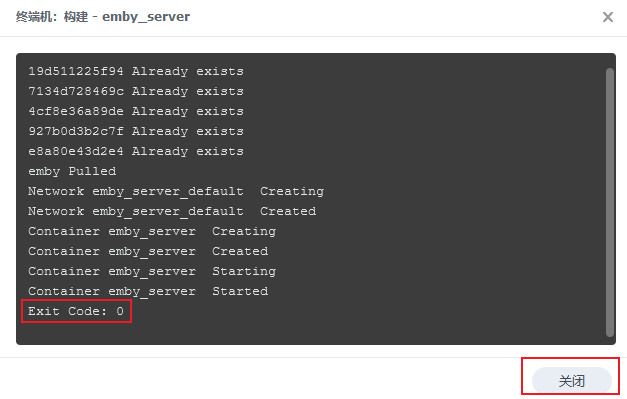 关闭后即可发现项目已正常运行:
关闭后即可发现项目已正常运行:
 此时可以根据自己配置的映射端口进行登录并操作emby了。
比如上面配置文件中最后有两句,这里我们把
此时可以根据自己配置的映射端口进行登录并操作emby了。
比如上面配置文件中最后有两句,这里我们把emby原来的端口8096(冒号右边)映射到了8095(冒号左边)上,原来的8920映射到了8919上,同时我们群晖的地址假设是192.168.1.15。
ports:
- 8096:8096 # 映射HTTTP端口
- 8920:8920 # 映射HTTTPS端口
那么我们需要使用这两个地址来登录emby:
http://192.168.1.15:8095
https://192.168.1.15:8919
这里不是说你一定要选择像我这样子映射,我是本地同时装了emby和jellyfin他们的端口一样,所以为了避免冲突,我将emby映射的端口进行了修改,使得这两个媒体服务器可以共存。
docker版jellyfin安装
这里同步提供一个jellyfin的,只需要将上一步的创建的emby_server和config再次针对jellyfin创建一份config和一份cache即可。
如下图:
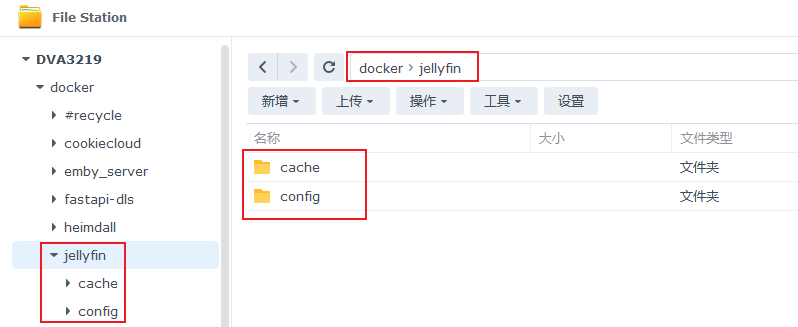 在按照上面同样的操作,直到这一步需要修改为
在按照上面同样的操作,直到这一步需要修改为jellyfin相关的选项:
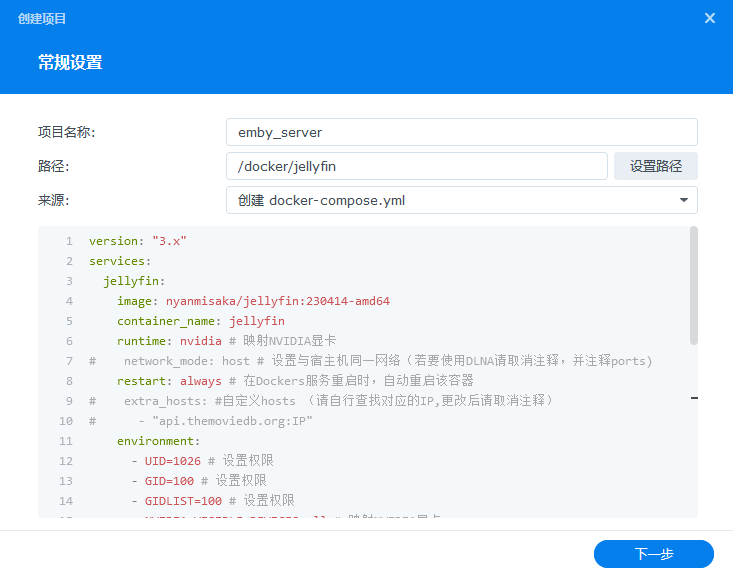 这里相关的配置项目如下(请复制后后确认没有其他附属信息):
这里相关的配置项目如下(请复制后后确认没有其他附属信息):
version: "3.x"
services:
jellyfin:
image: nyanmisaka/jellyfin:230414-amd64
container_name: jellyfin
runtime: nvidia # 映射NVIDIA显卡
# network_mode: host # 设置与宿主机同一网络(若要使用DLNA请取消注释,并注释ports)
restart: always # 在Dockers服务重启时,自动重启该容器
# extra_hosts: #自定义hosts (请自行查找对应的IP,更改后请取消注释)
# - "api.themoviedb.org:IP"
environment:
- UID=1026 # 设置权限
- GID=100 # 设置权限
- GIDLIST=100 # 设置权限
- NVIDIA_VISIBLE_DEVICES=all # 映射NVIDIA显卡
- NVIDIA_DRIVER_CAPABILITIES=all # 映射NVIDIA显卡
volumes:
- /volume1/docker/jellyfin/config:/config # 映射配置目录
- /volume1/docker/jellyfin/cache:/cache # 映射缓存目录
- /volume1/video:/video # 映射媒体库目录
ports:
- 8096:8096 # 映射HTTTP端口
- 8920:8920 # 映射HTTTPS端口
其他步骤和上面的emby相同。
docker版plex安装
也是需要单独创建一个针对plex目录和config和transcode.
最后输入下面这个配置信息即可:
version: "3.x"
services:
plex:
image: plexinc/pms-docker
container_name: plex
runtime: nvidia # 映射NVIDIA显卡
network_mode: host
restart: always # 在Dockers服务重启时,自动重启该容器
environment:
- UID=1026 # 设置权限
- GID=100 # 设置权限
- GIDLIST=100 # 设置权限
- NVIDIA_VISIBLE_DEVICES=all # 映射NVIDIA显卡
- NVIDIA_DRIVER_CAPABILITIES=all # 映射NVIDIA显卡
volumes:
- /volume1/docker/plex/config:/config # 映射配置目录
- /volume1/docker/plex/transcode:/transcode # 映射缓存目录
- /volume1/video:/video # 映射媒体库目录
纯命令启动
当然你也可以选择使用纯命令启动,只是没那么友好,镜像更新后直接更新可能显卡环境会丢失,所以更为推荐上面群晖自带yaml的方式。在ssh下以root用户,执行下面的命令用以启动emby/jellyfin/plex(没有任何字符,也不能有空格等字符)容器:
docker run \
--network=bridge \#设置网络模式
-p '8096:8096' \#映射http端口
-p '8920:8920' \#映射https端口
-v /volume1/docker/jellyfin:/config \#映射配置目录
-v /volume1/video/:/media \#映射媒体库目录
-e TZ="Asia/Shanghai" \#设置时区为上海
-e UID=1026 \#设置用户id -> 可以使用对应用户权限
-e GID=100 \#设置用户组id
-e GIDLIST=0 \#设置权限
--restart always \#在Docker服务重启时,自动重启此容器
--runtime=nvidia \#映射NVIDIA显卡
-e NVIDIA_VISIBLE_DEVICES=all \#映射NVIDIA显卡
-e NVIDIA_DRIVER_CAPABILITIES=all \#映射NVIDIA显卡
-e UMASK=000 \# 设置访问文件的权限
--name jellyfin \#容器名称
-d jellyfin/jellyfin:latest
这里新增的三条指令表示使用nvidia驱动,其他Plex和Emby等需要使用GPU的程序也是在原有的基础上添加这三句:
--runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=all \
-e NVIDIA_DRIVER_CAPABILITIES=all \
如果只有一个nvidia显卡,没有其他显卡,可以考虑使用添加下面这句代替上面这三句命令:
--gpus all \
比如Emby可以使用下面命令启动:
docker run \
--network=bridge \#设置网络模式
-p '8096:8096' \#映射端口
-v /volume1/docker/emby:/config \#映射配置目录
-v /volume/video/:/media \#映射媒体库目录
-e TZ="Asia/Shanghai" \#设置时区
-e UID=1026 \#设置权限
-e GID=100 \#设置权限
-e GIDLIST=0 \#设置权限
--restart always \#在Docker服务重启时,自动重启此容器
--runtime=nvidia \#映射NVIDIA显卡
-e NVIDIA_VISIBLE_DEVICES=all \#映射NVIDIA显卡
-e NVIDIA_DRIVER_CAPABILITIES=all \#映射NVIDIA显卡
-e UMASK=000 \#设置权限
--name emby \#容器名称
-d emby/embyserver:latest
比如Plex可以使用下面命令启动(具体意思对照上面的文档):
docker run -d \
--name=plex \
--net=host \
-e PLEX_UID=1026 \
-e PLEX_GID=100 \
-e TZ=Asia/Shanghai \
-e VERSION=docker \
-v /volume1/docker/plex:/config \
-v /volume1/video/:/media \
--runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=all \
-e NVIDIA_DRIVER_CAPABILITIES=all \
--restart unless-stopped \
plexinc/pms-docker
确保上述指令的正确性,关于上述其他指令的意思,可以通过网络进一步查询。
上面指令执行:
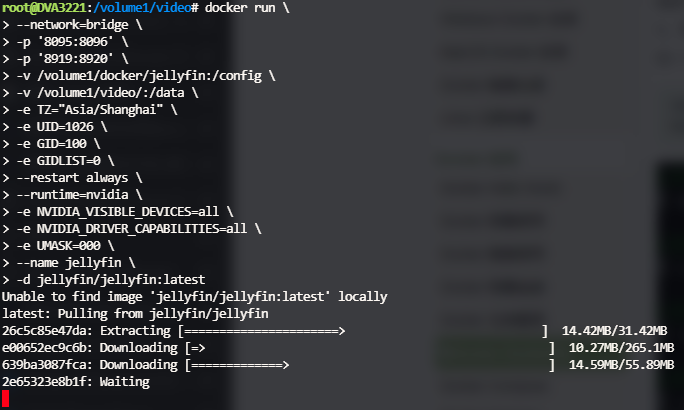 执行完成后该界面无报错就意味着完成了,可在群晖的
执行完成后该界面无报错就意味着完成了,可在群晖的Container Manager中看到新建的容器。
进入jellyfin中开启NVIDIA解码即可看到。
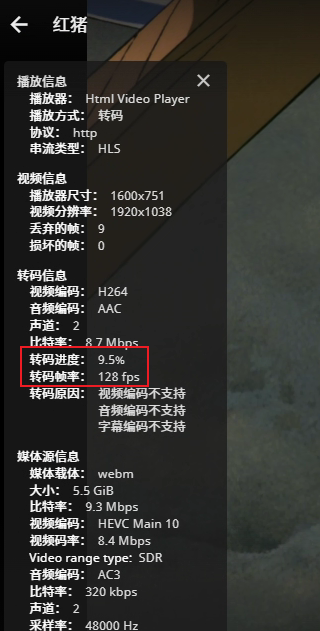
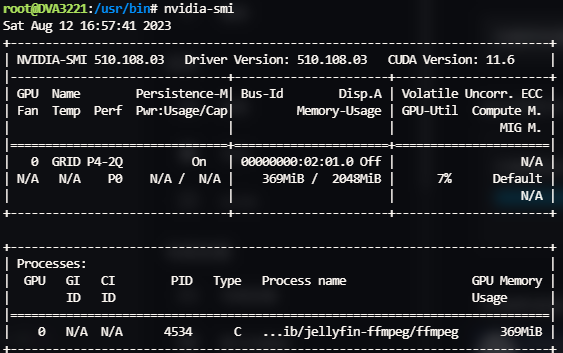 同样,在emby中也可以开启硬解:
同样,在emby中也可以开启硬解:
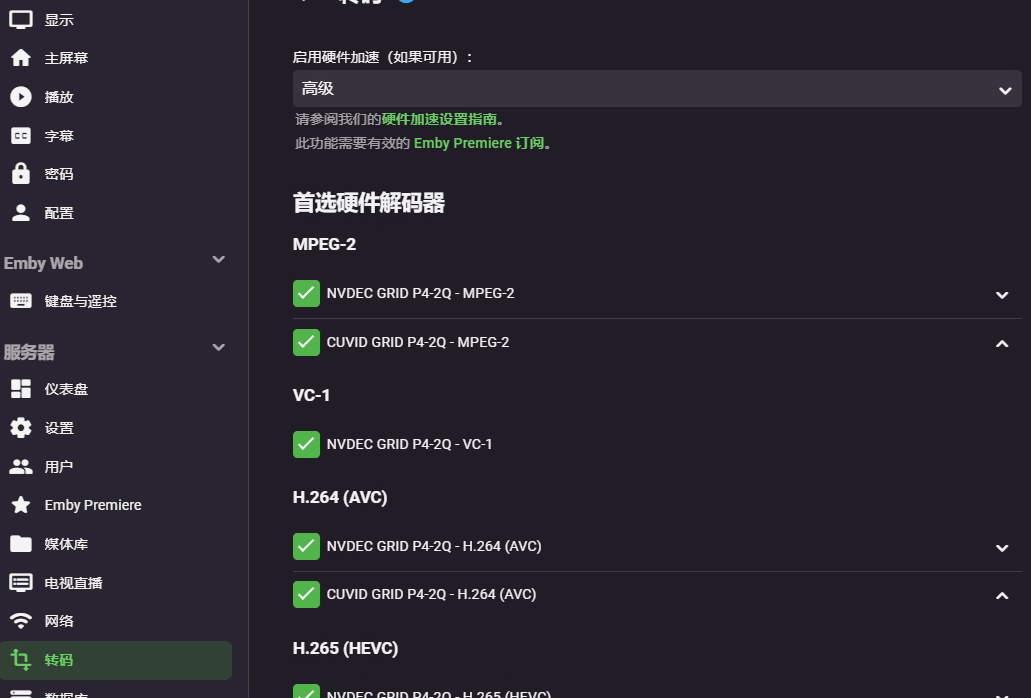
几个问题
问1:你这个支持哪些群晖系统? 答1:大部分的群晖7.2系统(linux 4.4.302+内核)都支持,但是XS+后缀的群晖是个例外,大部分的XS+系统不支持外(目前只发现1823xs+支持),如果你想要使用AI监控,需要是DVA系列,比如DVA3221和DVA3219都是推荐的系统,因为DVA3221原生提供了Nvidia GPU支持,系统中多处都对GPU的状态进行了展示,且监控默认包含8个授权,同时监控也可以选择使用AI等功能。
问2:相比官方原版和矿神大佬修改的版本有什么不同之处? 答2:
- 官方原版支持的功能,该版本都支持;
- 显卡vgpu功能开启后,可多个虚拟机共享GPU算力,比直通更高效利用GPU;
- 该版本的编解码支持更为完善,jellyfin、emby、plex的最新版本均可正常开启硬解;
- 集成了docker runtime,启动上述媒体服务器时参数更为简单。
- 没有原版存在的GDDR6限制,vGPU 14.4宣称支持的显卡,均可正常使用。
致谢
感谢佛西群的多位大佬指导,感谢佛西大佬送的五香牛肉干、kxxxm送的酸酸乳、卡布达送的三杯超大杯奶茶、ZZ的阿尔托送的奶茶、刕圐圙送的emby秘钥、无欲望亦无求、金蝶ERP、Nakano Azusa送的奶茶,以及以专业知识帮助无数小白成功硬解的专吃硬解。
遇到的问题答复
- 重启后因套件启动慢,而docker或者emby套件启动快,导致这两个套件无法使用GPU。(2023.08.27修复docker,其他套件信息需要更多测试)
解决办法:
- 手动重启一下无法使用GPU的套件(docker或者emby等)。
- 使用稍微修改一下下面脚本,放到计划任务开机启动即可。
- 最近比较忙,等我抽空修改一下,下一次更新优先修改这个。
!/bin/bash
sleep 30
bash /var/packages/ContainerManager/scripts/start-stop-status stop;
bash /var/packages/ContainerManager/scripts/start-stop-status start;
或者 (来自矿神)
synopkg stop ContainerManager
synopkg start ContainerManager
- 某些白裙搭配某些显卡无法使用该驱动
解决办法:
- 等待群晖适配新的显卡驱动
- 我可接单适配,因为白裙的孱弱性能,搭配高级显卡,我实在不知道啥应用场景,我自己也没这需求,太小众了。
- 某些黑裙直通搭配某些显卡无法使用该驱动
解决办法:
- 我没遇到,目前主流的黑裙+P4、2080Ti、40Hx、1050都测试支持。
- 群晖没理由需要那么强,那么新的显卡,群晖可以干的活一般1050Ti顶够了,其他需求建议使用ubuntu代替,实在有特殊需求可接单适配。
- 重启后套件/docker无法使用GPU,但可以看到GPU被占用(2023.08.27修复docker)
解决办法:
- 由于长时间没有下载回来授权导致,建议换一个自己本地搭建的授权服务器,参考地址 来自民间的VGPU授权fastapi-dls
- 下一版本会修复该问题。
- DVA3221可以看到GPU显示,其他系统为什么没有?
下一个版本适配(20230916适配完成)
- 使用DVA3221启动后为何系统崩了,进去系统管理页面输出
抱歉,您所指定的页面不存在
请严格按照教程安装驱动,因为DVA3221自带有NVIDIA的老版驱动,会出来捣乱。
- 我刚启动群晖的时候可以硬解,等半个小时后就不行了。
阁下使用的是vGPU吧,请注意,使用vGPU一定要有授权,不然启动的半小时后会限制性能,导致不可以使用硬解。可通过
nvidia-smi -q | grep "License"的输出确定是否有授权,输出这样子即是有授权
vGPU Software Licensed Product
License Status : Licensed (Expiry: 2024-2-1 16:5:24 GMT)
- 为什么我根据别的教程搭建的授权服务器可以正常给windows授权,但是不能给群晖授权?
请检查搭建docker的时区问题,此问题是时区造成的。
- 安装了最新版本的驱动套件之后,为什么我点击启动一会后会自动停止套件
套件新版本加入了检测机制,如果检查到系统中没有兼容的nvidia显卡会自动停止套件,这时候请检查是否正常连接了nvidia显卡,这个套件不是给dg1或者核显用的,请不要用这个套件来驱动非nvidia显卡,太老的显卡比如750Ti以前的也不支持(PS:10代以前的GPU其实编解码也很弱,建议拔掉独显提升性能)。
个人问题解答:
- 你做这个有什么收益吗?
答:目前只是知识层面的,博主本身在GPU行业从事驱动开发,在适配驱动的过程中学习行业标兵的做法意味着了解更多的底层设计,也利于博主在GPU方向有更广阔的见解;博主立志想要在GPU行业深耕,会持续不断的学习GPU知识。该次驱动的适配,只是学习路上的一次月考的答卷,只是有些人会输出成非常详实的文档,而我只是走了更远的一步,将其做出来并分享给所有有需要的人。
- 你做这个会走多远?
答:nvidia、amd、intel三家的技术我都会逐步开始学习,只要我还在这个行业,就一定会踏足上去,只是规划的路径的时间问题。
写在最后
非常感谢你能看到这里,皮蛋熊已经尽力把东西做的完善,如果你觉得皮蛋熊的努力值得肯定,皮蛋熊非常感谢你的支持。
如果你想交流心得,欢迎来 新QQ群 或者 TG群 一起吹水~(老Q群因不明原因被封,所以只加Q群有概率迷路)
如果皮蛋熊的努力解决了你的问题,不妨请皮蛋熊喝杯咖啡犒劳一下。

如果远方的朋友实力雄厚,知道皮蛋熊更喜欢吃烤鸭,想要犒劳皮蛋熊吃烤鸭:

or paypal: https://www.paypal.com/paypalme/pdbearme
在此,无比感谢愿意请皮蛋熊吃烤鸭超过88R的朋友,请凭记录直接加皮蛋熊Q好友([email protected]) 或者 TG好友(@dpawsbearr),皮蛋熊将会邀请你到体验/测试群中,你将获得额外的支持包括但不限于:
- 皮蛋熊将会尽力抽出时间解决你使用显卡的疑惑,问题等。
- 额外获得vGPU/GPU AI监控驱动的技术支持: 详见此网站
- 优先支持你提出的特性适配、问题修复等。
- 你有什么好玩的设备需要某些内核驱动级别的支持,皮蛋熊也会优先挤出时间进行学习适配。
- 不同厂家显卡的探索支持。


评论区